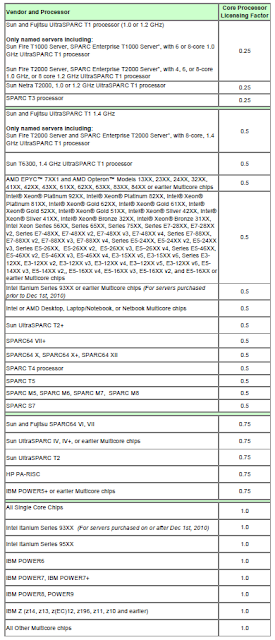
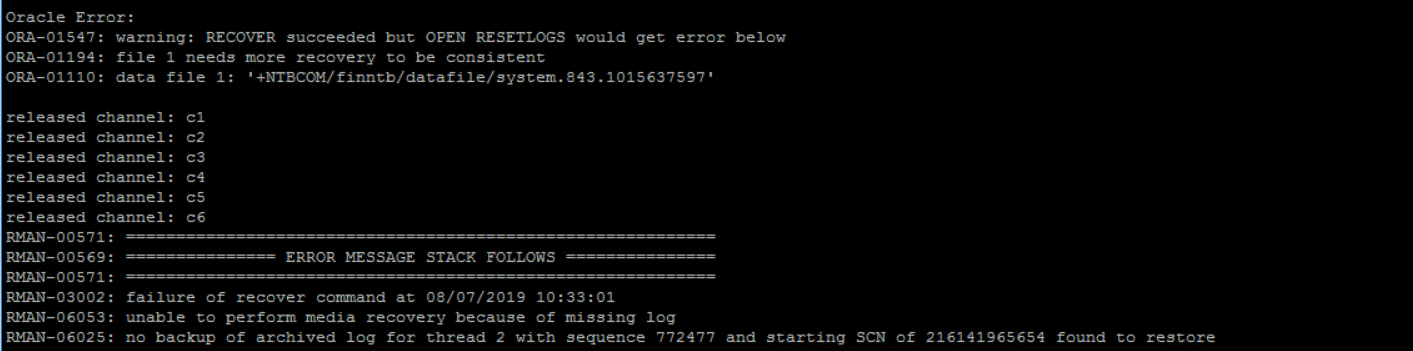
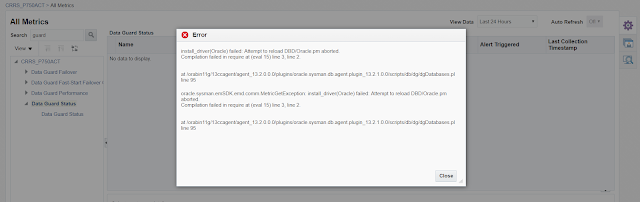
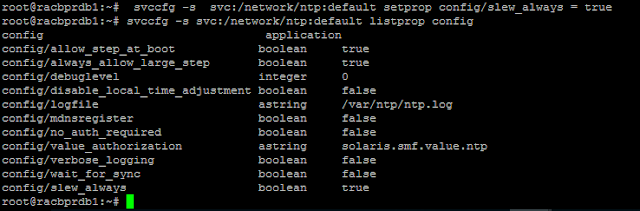
Stop AWS RDS instance using the CLI
The easiest method to start/stop AWS RDS instance based on schedule is by using AWS CLI inside a bash/bat script. Download and configure the AWS CLI. Install AWS CLI – https://docs.aws.amazon.com/cli/latest/userguide/install-windows.html Configure AWS CLI for the VPC – https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html CLI Commands. Use “rds stop-db-instance” and “rds start-db-instance” commands in a simple bat file as below, set userprofile=C:\Users\07766 aws rds stop-db-instance --db-instance-identifier qa-rds-ban aws rds stop-db-instance --db-instance-identifier dev-rds-ban aws rds stop-db-instance --db-instance-identifier uat-rds-ban It is required to set the userprofile of the user who configured the AWS CLI in the bat script set userprofile=C:\Users\<username> If you have not configured the AWS CLI using the security parameters, it is required to add below configuration to the script, aws configure set AWS_ACCES