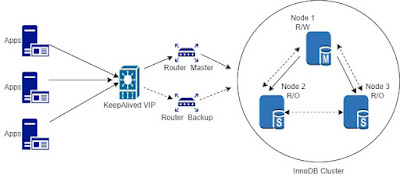
MySQL router kubernetes deployment
How to setup MySQL router in Kubernetes cluster? Continuing from previous post - MySQL router high availability for InnoDB cluster , in situations where application is deployed in kubernets it is better to incorporate mysql router to K8s itself. Inorder to deploy Mysql router in kubernetes two services are required along with the mysql router deployment. MySQL Router deployment Router deployment should listen on two ports for read write and read only connections. hostAliases are used to define the backend innodb cluster database servers. MySQL router docker image is used with variables - MYSQL_HOST, MYSQL_PORT, MYSQL_USER and MYSQL_PASSWORD. MYSQL_HOST variables should point to MySQL service defined in next section. mysql_router_deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: mysql-router namespace: default spec: replicas: 1 selector: matchLabels: app: mysql-router template: metadata: labels: app: mysql-router